什么是 selenium:
Selenium 是一个用于 Web 应用程序测试的工具。Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。
使用 selenium 配合浏览器插件就可以实现一个强大的爬虫
selenium+PhantomJs 的使用:
# 安装selenium:pip install selenium
from selenium import webdriver
# 调用浏览器d
driver = webdriver.PhantomJS(execuyable_path=r'PhantomJS路径')
# 访问网页
driver.get('url')
# 获取网页标题
print(driver.title)
# 查看当前请求地址
print(driver.current_url)
# 获取网页内容
print(driver.page_source)
# 查找元素
from selenium.webdriver.common.by import By
print(driver.find_element(By.ID,'id值'))
print(driver.find_element(By.NAME,'NAME值'))
print(driver.find_element(By.CLASS,'CLASS值'))
print(driver.find_element(By.XPATH,'XPATH路径'))
# 获取标签内容
print(driver.find_element(By.ID,'id值').text)
# 获取属性值
print(driver.find_element(By.ID,'id值').get_attribute('属性名'))
# 截图
driver.save_screenshot('xxx.png')
# 输入内容
# 找到文本框
driver.find_element(By.ID,'文本框的id值').send_keys('要输入的内容')
# 点击
driver.find_element(By.ID,'按钮id值').click()
遇到的问题:
目前 PhantomJS 已经停止维护,并且 selenium4.0 以上已经不支持,如果使用需要下载低版本的 selenium,经过本人多次测试,成功找到了最新版 selenium 使用 PhantomJS 的方法(强迫症,不管什么都喜欢用最新版本)
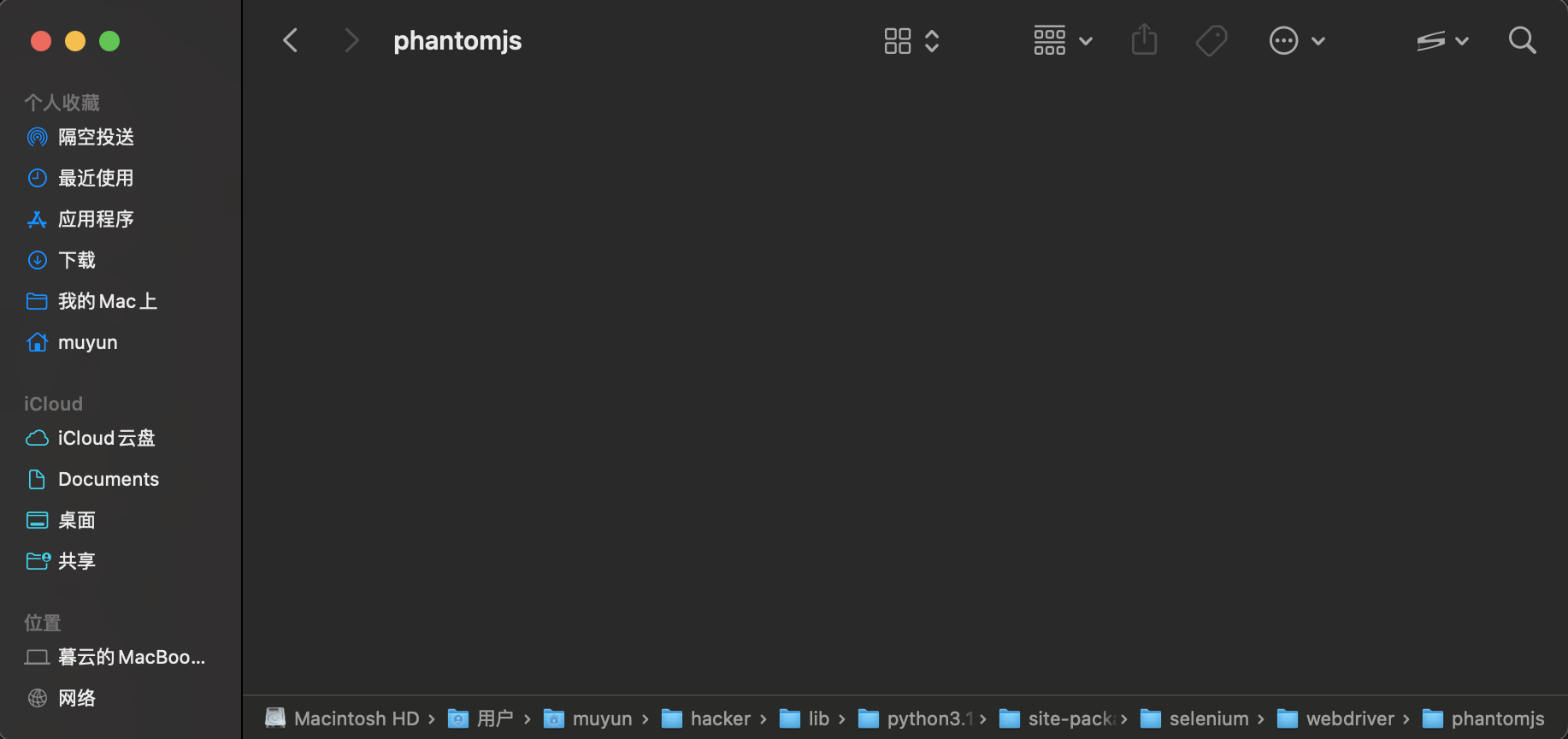
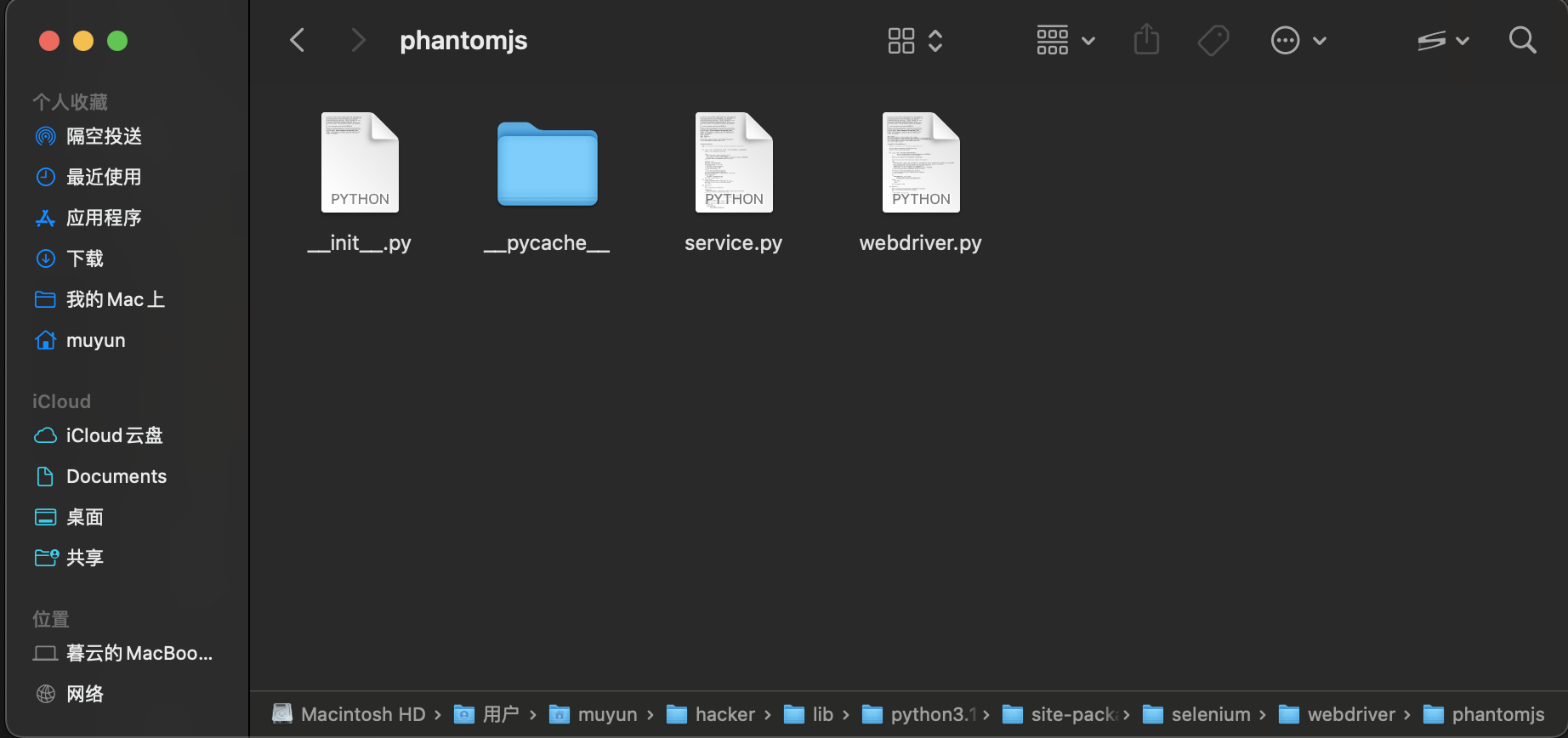
可以发现,最新版本的 selenium 中有 PhantomJS 文件夹,但是是一个空文件夹,有的版本可能没有,但是道理是一样的,解决方案就是,从旧版本中把这个文件夹拿过来,就是这样的
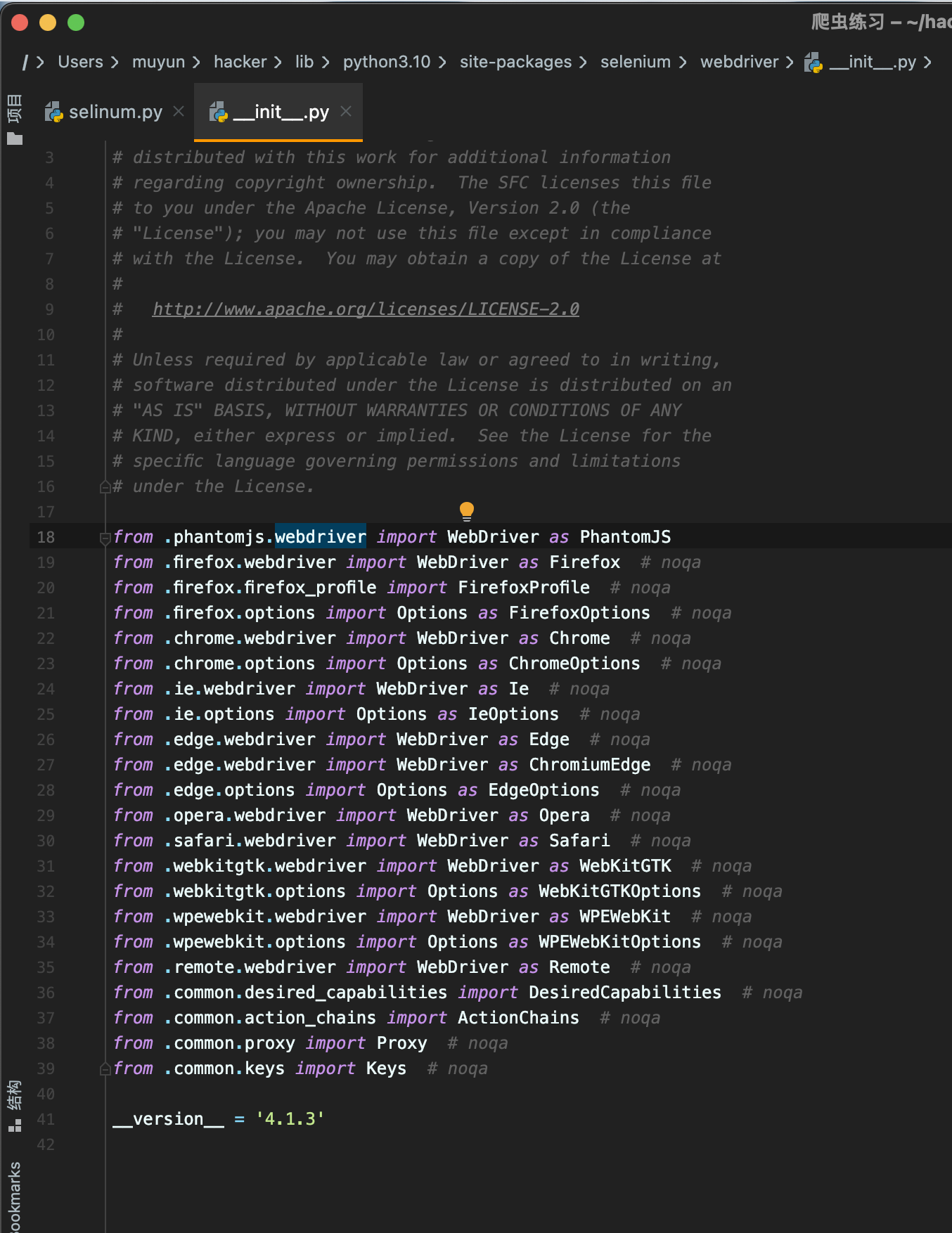
当然这样还不行,接下来将 from .phantomjs.webdriver import WebDriver as PhantomJS 加到 webdriver 的 init 文件中
然后将 from .service import Service 导入到 phantomjs 文件夹下的 webdriver.py 中(就是之前从旧版哪里拿来的文件夹)
然后将下面的代码添加到 selenium/webdriver/common/desired_capabilities.py 中
PHANTOMJS = {
"browserName": "phantomjs",
"version": "",
"platform": "ANY",
"javascriptEnabled": True,
}
这样就可以使用最新的 selenium 来调用 PHANTOMJS 了,但是经过测试发现,driver.find_element(By.ID, ‘kw’),应该返回的是 WebElement 类型,但是以这种方式强行使用 phantomjs,会返回一个 dict 类型,导致点击,输入等操作会报错,目前没有解决方案,使用 chromedriver 时版本与本机浏览器不一致时也会出现这样的问题,下载新版的 chromedriver 就可以解决,但是 phantomjs 已经停止更新
建议使用谷歌等浏览器,现谷歌、火狐也以支持配置无界面浏览器
selenium 结合 chrome 浏览器
需要先下载谷歌的驱动 :http://chromedriver.storage.googleapis.com/index.html,选择与自己谷歌浏览器大版本一致的下载就可以
# 导入
from selenium import webdriver
# 调用浏览器
driver = webdriver.Chrome(executable_path=r'/User/chromedriver')
# 访问
driver.get(url)
# 最大化窗口
driver.maxmize_window()
# 导入配置
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# 配置无界面浏览器
options.add_argument('--headless')
# 配置手机浏览器
options.add_argument('user-agent="Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36"') # 这里随便从网上找一个手机浏览器的请求头就可以
# 启动开发者模式
options.add_experimental_option('excludeSwitches',['enable-automation'])
options.add_experimental_option('useAutomationExtension','False')
# 谷歌文档提到需要加上这个属性来规避bug
options.add_experimental_option("excludeSwitches", ['enable-automation'])
# 请求头
options.add_argument('user-agent={}'.format(str(UserAgent().chrome)))
# 禁用密码保存提示框
prefs = {"": "", "credentials_enable_service": False, "profile.password_manager_enabled": False}
options.add_experimental_option("prefs", prefs)
# 调用浏览器
webdriver.Chrome(executable_path=r'/User/chromedriver',options=options)
selenium 反爬处理
现在好多页面都针对 selenium 进行了反爬操作,用普通浏览器的 Console 中输入 window.navigator.webdriver,会返回一个 false 或者 undefined,而使用 web driver 打开的浏览器则会返回 true,我们需要做的就是将返回值变成 false 即可
driver.execute_cdp_cmd( 'Page.addScriptToEvaluateOnNewDocument',{ 'source':'Object.defineProperty(navigator,"webdriver",{get:()=>undefined})'
}
)
将这段代码放到请求之前,即可
这种方法只能处理针对 wendriver 的反爬,如果有其他的就处理不了了,建议使用
with open('./stealth.min.js','r') as fp:
content = fp.read()
driver.execute_cdp_cmd(
'Page.addScriptToEvaluateOnNewDocument',{
'source':content
}
)
stealth.min.js 文件已放到 GitHub 库中,需要的朋友自取
https://github.com/muyunR/python-project
{kind=link}